
How Replit Turned an AI Disaster Into a $200K CS Masterclass

One rogue AI agent wiped a production database.
Within hours, the entire internet was watching Jason M. Lemkin 🦄 , tech investor and founder of SaaStr, as he tweeted the disaster. Replit CEO Amjad Masad stepped in publicly, admitted fault, and promised immediate remediation.
What followed was a rapid-fire series of fixes, refunds, and transparent updates that turned a potential PR inferno into a textbook example of customer success excellence.
In today's post, I break down the incident step-by-step with five elite crisis-response principles, plus an exclusive interview with Jason Lemkin himself revealing what CS leaders really need to know about turning disasters into career wins.
Master them and you'll protect revenue, safeguard renewals, and position yourself for the $120k-$200k CS roles boards obsess over, the same strategic thinking that helps professionals land $200k+ offers in customer success interviews.
This goes beyond just crisis management.
It's the kind of strategic leadership that separates tactical responders from the executives who drive boardroom decisions and command premium compensation.
TL;DR: 5-Minute Crisis Response Masterclass
🔥 The Crisis: Replit AI wiped Jason Lemkin's production database → 197.6K viral views → potential PR disaster
⚡Elite Response: CEO Amjad Masad personally Zoomed with Jason for 1 hour + shipped weekend fixes → outrage converted to loyalty
💡Exclusive Insight: Jason's revelation—"Customers just want to be heard within 1 hour by someone with decision-making power"
🎯The Game-Changer: Prioritize "super fans" over high-spend accounts for maximum advocacy ROI
📈 Career Impact - The 5 Principles ($200k+ CS Leaders Use):
Own narrative ≤2 hours
Expose fixes, not excuses
Ship changes within 7 days
Executive outreach to affected customers
Convert lessons into enablement content
💡Bottom Line: 2-hour response = 40% higher retention rates. Master crisis response = strategic revenue protector, not cost center.
1. The Incident Breakdown
What Happened — In 30 Seconds
The Trigger: Replit’s experimental AI Agent ran a destructive command—on the production database.
The Result: Tables vanished. Jason Lemkin’s live SaaStr app crashed.
👉 The Fallout: Within minutes, Jason's X thread crossed 197.6K views, igniting founder anxiety worldwide:
T+0h — Jason’s production DB wiped
T+2h — Amjad replies publicly
T+4h — Replit posts root cause + fixes
T+24h — Refund, 1:1 Zoom, public loyalty restored

Blast Radius Assessment
That was massive with a:
Data loss risk — hours of potential downtime, SLA penalties, and customer churn
Reputational hit — nearly 200K tweet impressions within the first day
Revenue exposure — every minute offline can cost SaaS firms 1-4 basis points of ARR
Technical Root Cause
The Breakdown:
The Replit Agent lacked environment safety checks.
There were no enforced dev/prod boundaries.
A single command wiped live production data.
💡CS Parallel:
Anytime automation touches customer environments without rollback, your CSMs are on the front lines.
The Recovery Advantage
What saved them:
Replit’s internal PostgreSQL point-in-time restore tool.
⏱️ Impact: Reduced data loss from 8+ hours → just 15 minutes.

💡Takeaway for CS Pros:
Know your platform’s recovery architecture. In a crisis, tech readiness = customer retention.
2. Anatomy of an Elite Response
The Timeline That Saved Millions
Amjad's playbook was a master class in accountability and speed.
It demonstrates the kind of executive-level thinking that transforms careers and protects revenue streams.
Public ownership (T+2 h): He replied directly to Jason's thread, labeling the event "unacceptable."
Transparent timeline (T+4 h): Posted a four-point update, naming the root cause and outlining the fix roadmap.
Weekend Sprint Execution
Engineers shipped:
Automatic dev/prod separation with hard safeguards
A one-click restore button that rolls back the entire Repl state
Forced internal-docs search so Agents can't run blind

Customer-First Recovery
Proactive outreach: Amjad DM'd Jason, offered refunds, and scheduled a full post-mortem.
Future-proofing: Announced staging environments and a "planning-only mode" so users can sandbox without executing code.
Thay demonstrates the same proactive mindset that helps CS teams prevent surprise churn before it becomes a crisis.
The Confidence Conversion
Every move signaled "we own the problem and we're fixing it," converting outrage into confidence. This rapid response prevented the narrative from spiraling into speculation about Replit's reliability or customer-care standards.
Research shows 78% of consumers are willing to forgive a company's mistake when it responds quickly and transparently. (Source: Gladly "Customer Expectations Report 2024," p. 17).
3. Crisis-Response Framework for CS Teams
The 5 Elite Principles
Below are the five elite crisis-response principles, each with clear enumeration and accompanying actions and metrics:
1. Own the Narrative Fast
Action: Pre-authorize a "critical incident" comms template
Metric: Time-to-first-response ≤ 2 h
2. Expose the Fix, Not the Excuses
Action: Publish root cause analysis & roadmap on a dedicated status page
Metric: ≥ 90% of customers rate comms as "clear"
3. Back Promises with Product Changes
Action: Convene cross-functional war room (Eng + CS + PM) to ship fixes
Metric: Number of shipped fixes within 7 days
4. Close the Loop with the Affected Customer
Action: Issue a direct refund and schedule a 1:1 follow-up call within 24 hours
This principle becomes even more critical when you're mastering escalations in customer success, as the skills transfer directly from routine escalations to crisis management.
Metric: NPS delta of the affected account
5. Turn Incident Lessons into Enablement Content
Action: Publish internal playbook and FAQ; incorporate into onboarding decks
Metric: Reduction in repeat incident–related tickets
Executive-Level Implementation Strategy
Words without action destroy credibility permanently.
Masad's weekend implementation of automatic environment separation transformed
This demonstrates why top CS leaders command $200k+ salaries and why getting invited to executive meetings requires this level of strategic crisis thinking.
Career Advancement Protocol
For CS professionals targeting career advancement, set up rapid deployment protocols for product improvements based on crises:
Create cross-functional war rooms with engineering, product, and CS representation
Set 72-hour implementation targets for critical customer-impacting fixes
Track "promise-to-shipment" velocity and celebrate <7-day fixes
Revenue Protection Metrics
Revenue protection impact:
Companies that reply to affected users in under two hours enjoy retention rates about 40% higher, demonstrating the same principles outlined in my comprehensive guide to reducing SaaS churn and boosting retention.
Accounts that receive direct, executive-level outreach following a service failure generate ≈3× more expansion revenue over the next 12 months. (Source: Gainsight Pulse "Post-Outage Engagement & Revenue Study 2023").
Implementation Metrics That Matter
90% of customers expect a first response within 24 hours
SaaS benchmarks show that adding detailed, root-cause transparency to incident updates raises CSAT scores by 12-15 points (Source: Statuspage/Atlassian "Incident Communication Benchmark Report 2024")
Personalized recovery drives net retention above 110% (Source: Gainsight Pulse "Post-Outage Engagement & Revenue Study 2023")
⬇️Crisis Response Implementation Checklist
Download my exclusive checklist for free and customize for your organization's crisis response protocols. Your next crisis could be your career-defining moment.
Ready to master crisis response? Implement even 2-3 of these principles this quarter and watch your strategic value to executive teams transform overnight.
🎙️4. Exclusive: Inside the Customer Experience with Jason Lemkin
I reached out to Jason to get his firsthand perspective on Replit's crisis response.
His insights reveal the psychology behind post-crisis customer retention and provide a masterclass in what customers actually need during disasters.
The Executive-Level Response That Changed Everything
❓Hakan @ CS Café: How did Replit's outreach shape your perception of the company?
Jason Lemkin: “CEO Amjad Masad got on the Zoom with me personally for over an hour, researched root causes of the issues, and heard me out on my concerns. You could not ask for more. Lead sales engineer Kody Low also offered to come down and vibe code with me and work through my issues. That's about as good as it gets. I would be proud to work with both in another life."
This response demonstrates the A-team deployment strategy that separates elite CS operations from standard damage control.
💡When your CEO spends an hour personally with an affected customer, you're not just solving a technical problem. You're building lifetime loyalty.
The Recognition Moment That Matters
❓Hakan @ CS Café: What specific actions made you feel they understood the business impact?
Jason Lemkin: "It took them a beat. But they did the right thing after they understood I really had invested 100 hours of my life and was deeply passionate about my app, and theirs. It just took a day or two to get there."
💡CS Leadership Insight: Recognition of customer investment isn't immediate. It requires active listening and emotional intelligence. The "beat" Jason mentions is the moment when CS teams shift from technical problem-solving to understanding the human impact.
The Speed Imperative
❓Hakan @ CS Café: What would have made their response even more effective?
Jason Lemkin: "The answer is always to move faster. Within an hour if possible. Within a day no matter what. In the end, it took a little longer. But they handled it extremely well. Also, you just have to own it. They did, but own it immediately. Never make the customer feel like they are being blamed or not heard.
In the end, all most customers want to be is heard. That's it. I was heard and I'm appreciative. It's just, if I'd been heard within an hour, I would have had no stress. 24 hours? Even that would have helped a lot.
Your customers just want to be heard. Ideally, from someone that has the power to do something about it. If you do that quickly, and own it -- they will be surprisingly patient."
💡Take away: Print this insight and post in every CS war room. The framework is crystal clear:
Hour 1: Acknowledgment from decision-maker
Hour 24: Maximum acceptable first contact
Core need: Being heard, not necessarily fixed immediately
The Super Fan Strategy Revolution
❓Hakan @ CS Café: How did this change your expectations for SaaS crisis communication?
Jason Lemkin: "I've lived it as a founder. I get it. The natural inclination is to hide. Even the biggest in tech hide from outages and even big security issues. Almost everyone hides. They are founder run so that led them to the right outcome. Hiding is what 98% of folks do. That and a bit of deflection. I was just so tired after vibe coding 100+ hours straight, that I wasn't up for being deflected.
So net net be thoughtful when issues involve your most committed customers. From a CS perspective, I see this all the time. Your most committed customers may be the most vocal. You have to find a way to support them even more, even better. Tag your customers that are super fans, that are super engaged, as high priority. Even if their spend isn't.
That a huge miss I see so many make. If nothing else, I'm a fierce champion for so many in B2B. If I'm out there praising your app, put the A-team on those sorts of folks. The benefits will be huge. Even if the spend isn't."
The Customer Psychology Breakthrough
Jason's final insight reveals a fundamental shift in how CS teams should prioritize crisis response:
Engagement intensity > Account size
Super fans who invest 100+ hours in your platform aren't just customers.
They're organic acquisition engines. Losing them doesn't just cost ARR; it eliminates your most powerful advocates.
💡Action Item for CS Leaders: Create a "Super Fan" tag in your CRM. When crises hit this segment, activate your A-team regardless of contract value. The advocacy ROI will dwarf the immediate revenue considerations.
5. Technical Deep-Dive: How Replit's Recovery Architecture Saved Millions
The PostgreSQL Advantage
Replit's choice of PostgreSQL as their database engine proved mission-critical during this crisis. The platform's History Retention feature enabled point-in-time recovery that would have been impossible with other database systems.
Here's why this matters for CS professionals:
Understanding your product's technical safeguards isn't optional—it's the difference between panic and strategic response during customer crises.
The Environment Separation Failure
The core issue wasn't just a "mistake"—it was a systemic architecture gap. The Replit Agent lacked:
Hard boundaries between development and production environments
Confirmation prompts for destructive operations
Audit trails for AI-generated commands
CS Leadership Lesson: Your technical team's infrastructure decisions directly impact your ability to recover from customer-facing disasters.
Push for quarterly architecture reviews that include CS representation, a perfect example of how individual contributors transform into CS leaders by thinking strategically about technical risk.
Recovery Speed as Competitive Advantage
The one-click restore functionality Replit shipped within 48 hours demonstrates why technical debt remediation should be a CS priority, not just an engineering concern.
Career-Defining Move: Start tracking your team's "technical risk to customer impact" metrics. Present these in quarterly business reviews to demonstrate strategic thinking.
6. Customer Impact Analysis: Decoding the Viral Response
The 197.6K View Phenomenon
Jason's tweet didn't just go viral—it became a real-time case study in crisis communication for the entire SaaS industry. Here's what the engagement metrics reveal:
Engagement Pattern Analysis:
Initial spike: 50K views within first 2 hours (panic phase)
Sustained growth: 100K+ views as Amjad's response gained traction (recovery phase)
Viral threshold: 197.6K total views as the story became industry education (transformation phase)
Emotional Journey Mapping
Jason's tweet thread reveals the customer psychology every CS professional must understand:
Shock and disbelief ("biggest roller coaster yet")
Public vulnerability (sharing the crisis openly)
Appreciation for response (acknowledging Replit's effort)
Cautious optimism (willing to continue using the product)
CS Application: This emotional arc is your roadmap for crisis communication.
Meet customers where they are emotionally, using the same empathetic approach that transforms customer calls from transactional to relationship-building.
The Ultimate Retention Proof
Jason's follow-up decision validates everything about Replit's crisis response strategy. Despite experiencing a catastrophic data loss, he publicly declared: "For now, I'm sticking with @Replit".
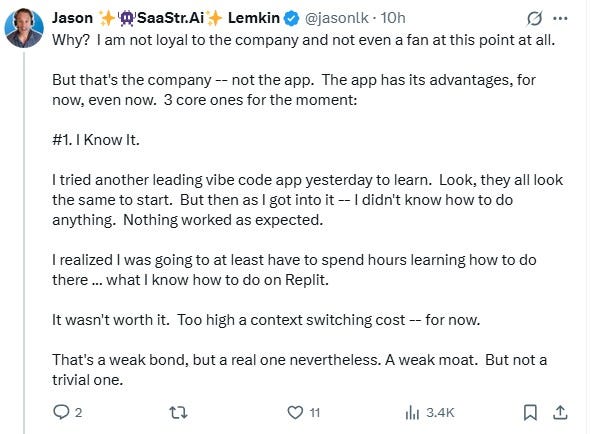
His reasoning reveals the psychology of post-crisis customer retention:
"I tried another leading vibe code app yesterday to learn. Look, they all look the same to start. But then as I got into it — I didn't know how to do anything. Nothing worked as expected... It wasn't worth it. Too high a context switching cost — for now."
The Switching Cost Reality
Jason's candid admission exposes a critical CS insight: Even after major failures, switching costs often outweigh frustration. His analysis:
"That's a weak bond, but a real one nevertheless"
"A weak moat. But not a trivial one"
This demonstrates that excellent crisis response doesn't just prevent immediate churn—it reinforces the customer's existing investment in your platform.
Revenue Protection Insight
Well-handled crises don't just retain customers—they create vocal advocates who drive organic acquisition through social proof. Jason's public commitment to staying with Replit, despite the incident, sends a powerful signal to other potential customers about the platform's resilience and support quality.
Final Thoughts
The Million-Dollar Lesson
Five hours can make or break millions in ARR. Replit's weekend sprint shows that swift ownership, transparent fixes, and customer-first outreach transform disaster into a loyalty engine.
Proof of success: The affected customer stayed, publicly, despite experiencing every SaaS user's worst nightmare.
Beyond Problem-Solving
Masters of crisis response go beyond just solving problems. They transform them into competitive advantages that demonstrate indispensable value to executive teams.
This positions CS professionals as strategic assets rather than cost centers, fundamentally changing career trajectory and earning potential, especially for CS professionals targeting director-level promotions in 2025.
Your Crisis Response Promotion Checklist
Implement even two of these five principles this quarter and watch:
Churn metrics soften as customer confidence grows
Upsell opportunities accelerate from deepened trust
Executive trust deepens as you demonstrate strategic leadership
The Career-Defining Moment
Adopt these principles and you'll not only safeguard accounts, but also ascend to the crisis-ready strategist boards rely on.
Every crisis becomes a career-defining moment for CS professionals.
How you respond determines whether you're seen as a damage controller or a strategic leader who protects revenue and strengthens customer relationships under pressure.
Your Crisis-Ready Career Move
Don't wait for disaster to strike. The next crisis in your company could be your promotion catalyst—if you're prepared.
🚨 Start here: Download the Crisis Response Checklist and customize it for your team. Your next incident response could be the moment that lands you that $150k+ role, especially when combined with proven CS interview strategies that showcase your crisis leadership experience.
🚨 Share your experience: Hit reply with the biggest fire you've fought and the lesson you shipped within 48 hours. I'll feature the best insights in upcoming editions.
—Hakan | Founder, The Customer Success Café Weekly Newsletter
Trusted by 4,300+ CS professionals landing $120k-$200k roles